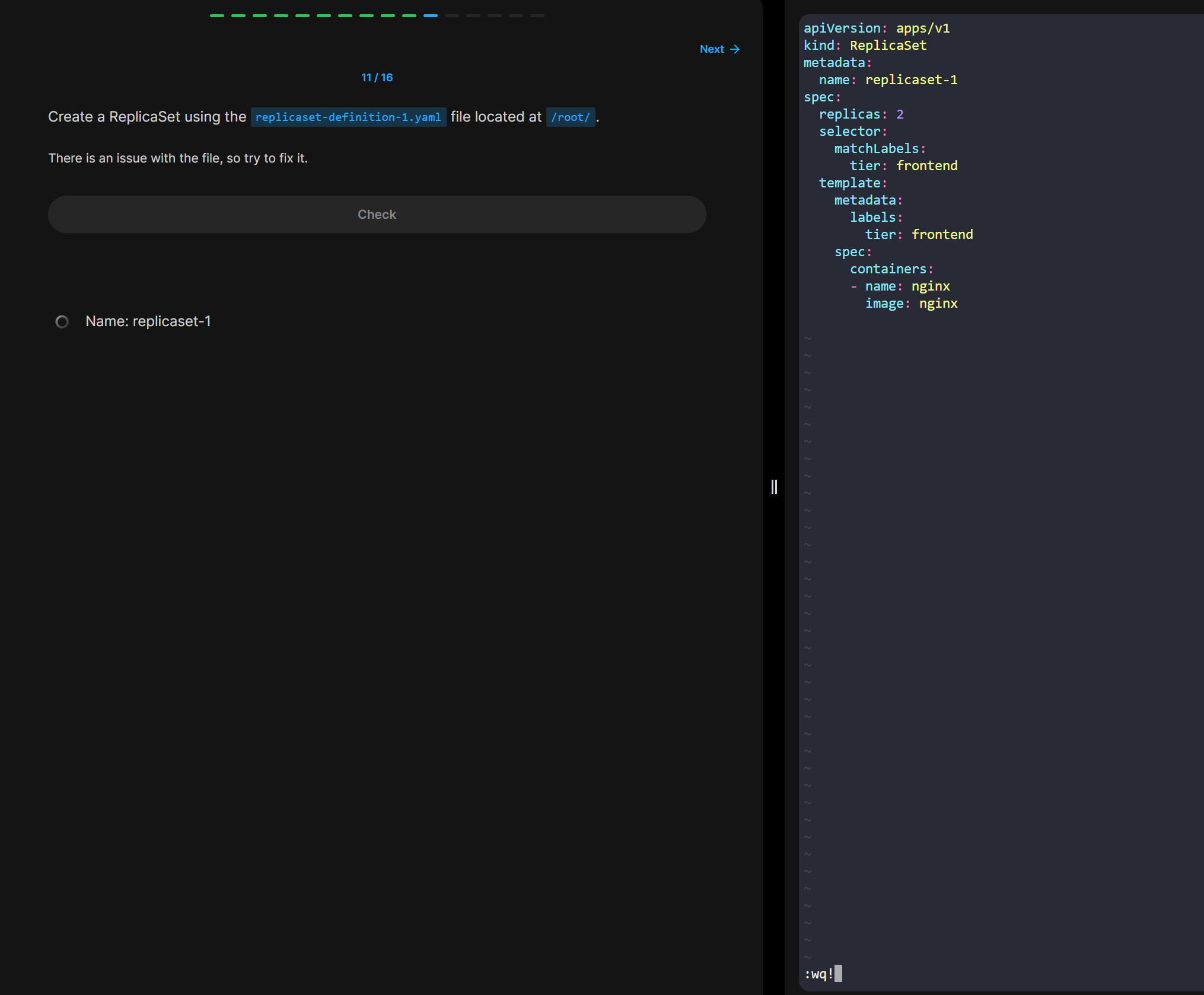
※ 틀린 정보 존재 가능!!
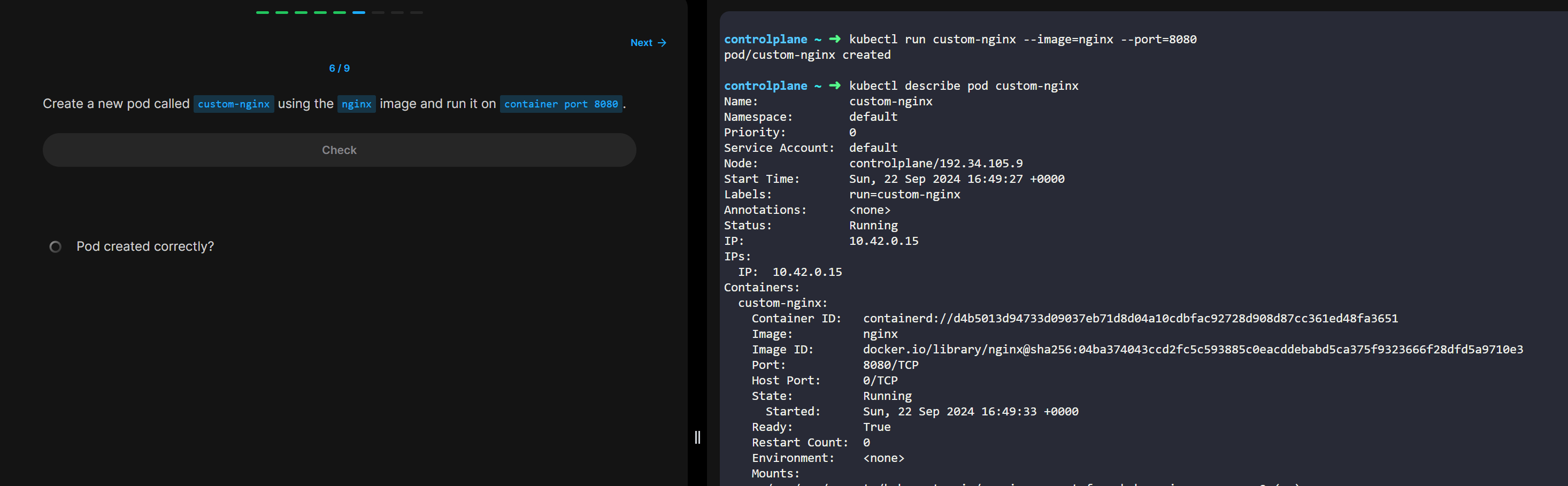
• VM
○ 컴퓨터라고 보면됨. 각각 VM마다 OS 가 있음.
○ 그 OS를 돌리는데에 자원이 필요함.
○ 로컬 컴퓨터 안에 가상컴퓨터 깔면 그 안에 Windows가 될 수도 있고 linux도 되고, 그래서 컴퓨터 안에서 컴퓨터를 조작하고 갖고놀 수 있는데 그런거 해봤으면 이해가 빠름
○ OS위에 여러 어플리케이션 집합시켜서 서비스 돌릴 수 있음.
§ 단점:
§ VM이 여러개면 각각마다 OS가 있어서 그 자원을 잡아먹는게 아까움.
§ 라이브러리 버전을 바꿔야 한다 하면 각각VM마다 다 업글해주고 그래야함 - 번거로움
§ 하나의 시스템 안에 여러개의 어플리케이션이 있어서 그 VM가 보안에 뚫리면 그 안 어플리케이션 전체가 보안에 취약해짐
• 노드(VM라 봐도 됨)
○ 얘도 컴퓨터임. OS도 있음
○ VM은 하나의 VM이 여러개의 어플을 갖고 돌린다면, 노드는 개별 앱을 갖고 돌림. (꼭 안그래도 되는데 그래야 가벼워지고, 확장성이 좋아지며 MSA를 만드는데 의미가 있음)
○ 각각 노드는 독립적이어서 네트워크도 달라버림. 그래서 하나가 뚫려도 하나만 뚫리지 나머진 안전함
• 클러스터
○ 노드가 모이면 클러스터가 됨
• 컨테이너
○ 뭔가 어떤 어플을 돌리기 위한 여러가지 요소들을 합쳐놓은 패키지임.
○ Docker가 컨테이너 그 자체임. 도커라이즈 한다는거 자체가 이미지를 만드는건데 그 이미지 안에 여러가지 짬뽕 앱들이 섞여서 어떤 시스템을 만들 수 있음.
○ 컨테이너는 그 자체로 존재할 수 있음. OS없어도 컨테이너 런타임(도커같은거)만 사용하면 시스템이 돌아감.
• 그래서,
○ MSA는 어떻게 구성되냐
§ 적절히 커다란 하드웨어 리소스가 있음
§ 그 리소스를 어느정도 써서 클러스터를 띄움
§ 클러스터 안에는 노드들을 띄움.
§ 클러스터는 노드들을 Orchestration 함 (지휘 함)
□ 지휘 한다는게 뭐냐면 여러 노드들에게 자원을 분배할 수도 있고, 노드가 뻑나면 죽였다 살리기도 하고, 노드를 하나 더 만들고 싶으면 만들고, 모니터링을 하겠다 하면 하고 그런거
§ 노드 안에는 pod들이 뜸.
§ pod는 가장 최소화된 단위임. 그것들이 서로 API 통신을 하든 뭘 하든 어깨동무하면서 시스템을 하나 만들어서 서비스가 돌아갈 수 있게 함
○ 그런 행위를 하면 뭐가좋냐
§ 첫째 - 유연해짐.
□ 만약 VM 배포를 하는 시절이었으면, 내가 뭐 버전업을 해야함. 그럼 각각VM에 전부 그 버전으로 올려야댐
□ VM 안에 앱 하나가 고장나버렸어, 그럼 VM안에 같이있던 다른 앱들까지 손해를 오지게봄
□ MSA 구성을 하면 라이브러리 참조를 하는 컨테이너만 삭 업글 해주면 나머지가 그걸 보고 알아서 업글 가능
□ 앱이 몇개 고장나도 미리 2~3개 복제해서 띄워놨다면 다른 서비스에 손해가 가지 않음
§ 둘째 - 인간이 편해짐
□ 개발자/운영자가 해야할 일이 줄어듬 왜냐면 저 시스템이 알아서 해주니까.
□ 뭘 알아서 해준다고? 자원분배, 고장나면 죽였다 살리기도 하고, 오버헤드가 쌓이면 수평적으로 오토스케일링도 해주고, 그런게 되는게 개꿀임.
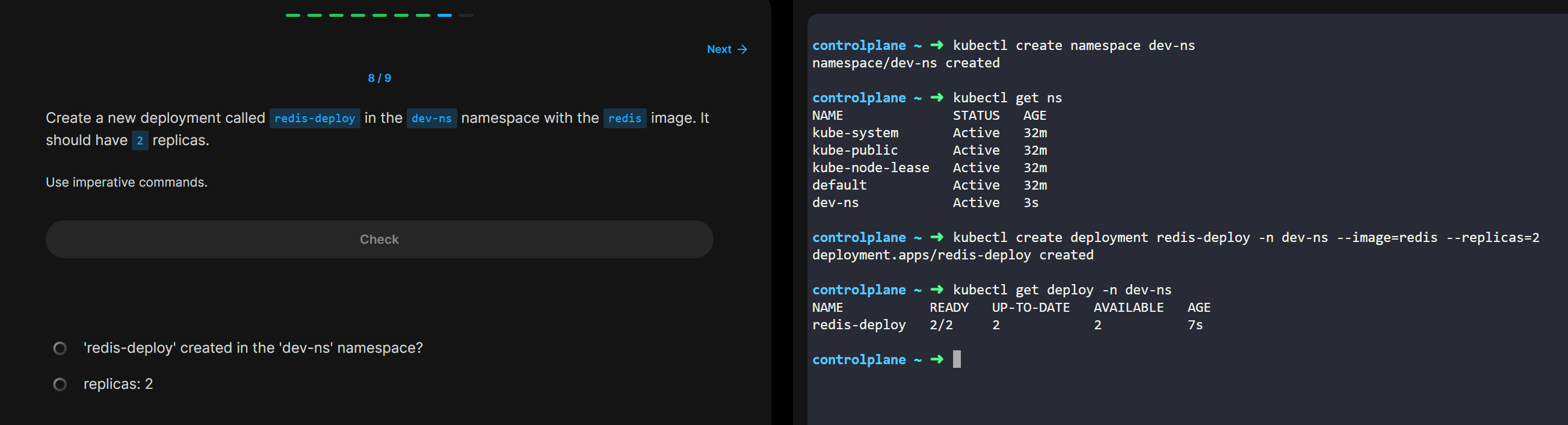
• 네임스페이스
○ 근데 하나의 클러스터 안에 여러개의 컨테이너가 뜬다했잖아
○ 너무 많이 떠버려서 막 혼잡해 그럼 불편하잖아
○ 그래서 좀 시스템별로 분리해서 띄우고싶으면 사용하는게 Namespace
○ 그 종류는 다음과 같음
§ 마운트mnt, 프로세스ID(pid) , 네트워크net, 네트워크 간 통신ipc, UTS(Unix timestamp??, 사용자 ID(user)
• Docker
○ 한마디로, 모든걸 짬뽕시킬 수 있는 간편한 포터블 패키지 툴
○ OS가 달라도 Docker을 사용하면 뭘 패키징 했는지 내부 확인 가능
○ 왜냐면 앱을 실행하기 위한 환경 자체까지 패키징 할 수 있어서.
• 도커 기반 컨테이너와 VM 이미지의 차이
○ 도커는 컨테이너 이미지가 여러 레이어로 구성되어 있음
○ 레이어들은 여러 이미지에서 재사용 가능함
○ 동일한 레이어를 포함한 컨테이너 이미지를 실행할 때는 이전에 다운로드 된 것을 제외하고 다운해서 빠름.
• Docker의 주요 개념
○ 이미지
§ 애플리케이션과 환경을 패키지로 묶는 것.
○ 레지스트리
§ 도커 이미지를 저장, 사람들간에 이미지를 공유할 수 있는 스토리지임
○ 컨테이너
§ 도커 기반 컨테이너는 곧 리눅스 컨테이너임
§ 실행중인 컨테이너끼리는 완전히 독립적.
• 근데 계속 독립적이라고 하는데, 어떻게 독립적인 녀석들끼리 동일한 파일 공유 가능?
○ 이미지 레이어 때문임
○ 여러 컨테이너는 같은 이미지를 사용하면 그걸 베이스 이미지로 공유해서 씀
○ 그런데 만약 여러 컨테이너 중 한 놈이 그 이미지를 갈아끼워버리면, 갈아끼운 놈은 베이스 이미지가 바뀌어서 예전걸 볼 수 없음 (나머진 여전히 공유함)
○ 이것은 컨테이너 이미지 레이어가 읽기 전용이기 때문에 동작함
• 컨테이너가 자체 커널을 두기 때문에 발생할 수 있는 일
○ 몇몇 앱이 특정 커널 버전을 요구하면 그 앱은 돌아가지 않음.
○ 또한, 하드웨어 아키텍처가 달라도 안됨
§ 예를들면 x86 아키텍처, 또는 ARM 기반 시스템
• rkt
○ 도커와 같은 컨테이너 실행 플랫폼임. 리눅스 컨테이너 엔진임.
○ OCI => 컨테이너 형식 및 런타임에 대한 개방된 업계 표준
○ rkt 는 OCI를 따름. 도커도 OCI 의 일부. 따라서, 도커 컨테이너 이미지를 rkt도 실행 가능.
• 쿠버네티스
○ 간략한 역사
§ 구글이 만듬
§ 얘낸 수십만 대의 서버를 운영, 엄청난 규모의 배포관리를 처리해야 했을 것, 그래서 수천 개의 소프트웨어 구성 요소를 개발하고 배포할 때 효율적이고 비용적게 들게 관리할 수 있는 솔루션을 만듬
§ 2014년 나옴
○ 작동법?
§ 리눅스 컨테이너 기능을 사용
§ 마스터 노드가 있고, 여러개의 워커노드로 구성됨.
□ 마스터 노드에 어플리케이션 manifest 를 제출하면 걔가 워커노드 클러스터에 삭 배포쎄림.
○ 쿠버네티스가 유용한 이유
§ 특정 인프라 관런 서비스를 애플리케이션에 구현하지 않아도 됨
§ 쿠버네티스가 다 해주기 때문.
§ 뭘 해주냐고? - 서비스 검색, 확장, 로드 밸런싱, 자가 치유, 리더 선출.
§ 그래서 개발자는 개발만 하면 된다.
○ 아키텍쳐
§ 마스터 노드 -> 워커 노드
§ 마스터 노드
□ 컨트롤 플레인 이라 부르는듯
□ 사용자와 컨트롤 플레인과 통신하는 쿠버네티스 API서버
□ 스케쥴러 역할
□ 구성 요소 복제, 워커 노드 추적, 노드 장애 처리 등 클러스터 수준 기능을 수행하는 컨트롤러 매니저임
□ etcd는 일종의 저장소인데 키-값 형태를 띰. 얘는 클러스터 구성을 지속적으로 저장함.
§ 노드
□ 노드는 마스터노드와 kubelet 이라는 API통신을 통해 구성 설정을 공유함
□ 애플리케이션 구성 요소 간에 네트워크 트래픽을 분산하기 위해 kube-proxy 를 씀.
○ 실행중인 컨테이너 유지
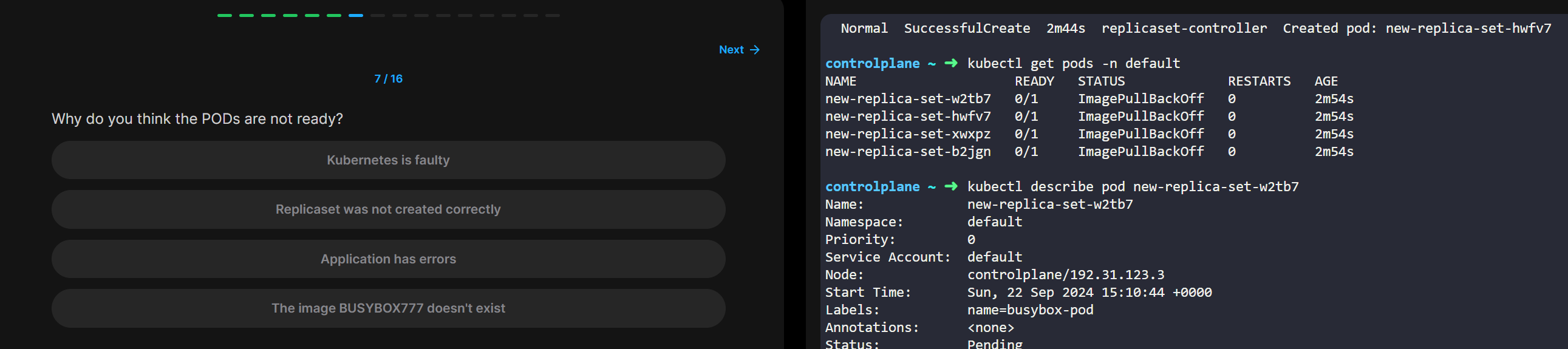
§ 사용자가 딱 5개의 pod만 뜨게 설정했다
§ 그럼 5개가 뜬다. 그런데 이상하게 1개가 뻑나서 안뜨고있다?
§ 그럼 자동으로 얘 죽이고 다시 하나 새로 띄운다. 그런식으로 사용자가 지정한 설정대로 유지하려고 함.
§ 노드도 마찬가지.
§ 노드의 상태가 메롱이야. 그럼 노드 안에 실행되고 있는 컨테이너들을 다른 노드에 싹 옮겨서 살려낼라고 함.
○ pod 수 확장 가능
§ 복사본 만들어서 늘리기, 줄이기 다됨.
§ 적절한 갯수를 쿠버야 너가 알아서 해줘 하면서 맡기기도 가능
§ CPU, MEM, 초당 쿼리 이런 것들도 설정 가능
○ 분산되어있는 컨테이너들이 서로 어떻게 연결하는지
§ 노드상태가 메롱이거나 하면 pod들이 다른 노드로 옮길수도 있고 클러스터를 옮길 수도 있고 그런데, 그러는순간 연동이 끊기는거 아닌가 싶으나
§ 미리 동일한 서비스를 제공하는 컨테이너의 정보와 모든 고정 IP 주소를 공개하고 그걸 클러스터 내에 노출시키면 pod들이 알잘딱으로 통신 한다
§ 이런 방법은 환경 변수를 통해 만들어내고,
§ 또다른 방법으로는 DNS를 통해 서비스IP를 조회할 수도 있씀
○ 앱 배포 단순화의 실현
§ 쿠버네티스가 모든 서버에 배포되어있음
§ 클러스터 다 떠있고, 리소스 할당 잘 받았음.
§ 개발자가 이제 할 건 어플리케이션 배포만 잘 하면 됨
§ 사실 배포도 딱히 할거없음. 버튼1회 누르면 자동으로 빌드, 도커라이즈, 배포 다 해줘서 인스턴스 뜰때까지 그냥 보고만 있으면 됨
§ 클러스터 구성 서버가 뭔지, 알바가 아님. 그걸 관리하는 사람은 따로 있으면 됨
§ 그니까 개발자가 원래 개발/운영/배포 다하는 devops 성향을 갖는 시기가 있었는데 그게 너무 할일도 많아지고 번거로왔는데, 이제 개발자는 개발에 몰두할 수 있게 됐다는게 핵심
○ 하드웨어 활용이 높아짐
§ 왜냐면 어플 배포할 때 어느정도 리소스를 먹으면서 올라갈텐데
§ 클러스터 내 여러 노드가 떠있을 때 가장 적절히 리소스가 여유로운 쪽에 어플을 올려다놓음.
§ 그래서 어느 한 쪽이 부하가 일어나지 않고 잘 배분함.
§ 이런게 솔직히 인간이 하기엔 번거롭고 쉽지않음. 언제 그거일일히 다 보고있음.. 노드가 적은것도 아니고 막 수십개면 불가능한것임.
○ 상태를 자기스스로 파악하고 지혼자 치유함
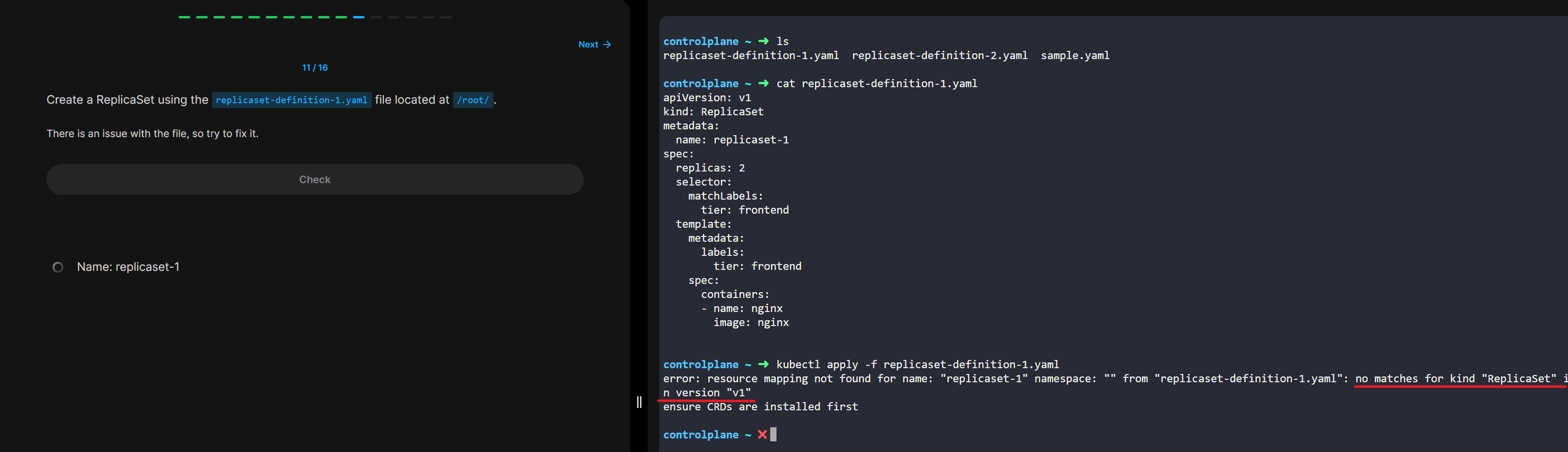
§ 위에도 썼던거 같은데 노드가 상태가 메롱이야. 또는 pod가 말을 안듣고 장애가 나버렸음
§ pod를 즉시 kill 때리고 다시 띄움. 잘 돌때까지. (처음 잘 떴다면, 그 다음 죽는 경우는 보통 어떤 예외상황 때문이며 kill 당하고 새로 살아났는데 또 kill 당하는 무한반복이 일어난다면 그건 개발자가 실설정실수했을 확률높음 그건 배포하고 모니터링 후 바로 조치 해야됨)
§ 노드 상태가 이상하다 하면 그 안에 떠있는 컨테이너들을 빨랑 다른 가용한 노드로 옮겨서 살려냄.
§ 그럼 일단 서비스는 살아있는 상태가 되는거.
§ 그 사이에 고장난 노드에 대한 점검을 개발자가 하든지 하면 됨.
§ 특히 그런 노드 장애가 새벽에 발생했다고 해보면 노드내 컨테이너를 일단 살려내 놨으니 그 즉시 장애를 치유할 것이 아닌 아침에 출근해서 확인해도 되는 부분인 것.
§ 즉, 쿠버네티스가 삶의 질을 높여준다는 것.
○ 오토스케일
§ 어떤 서비스에 갑자기 사용자가 엄청 몰려서 부하가 씨게 일어났음
§ 리소스량이 막 한계를 초과해서 터질라함
§ 오토스케일을 설정했다면 문제없다. 어느 정도의 부하가 발생하는 것이 캐치되면 pod 수를 자동으로 늘려서 부하를 분산시키는 작업을 알아서 해줌.
§ 부하가 줄어들고 어느정도 시간이 지나면 다시 pod 수를 낮춰서 정상으로 돌려놓는다.
§ 오토스케일이 없었으면 이미 서비스 뻑나서 503 장애발생했을건데 그걸 막아준다. 최고다.